
Recently, I had the opportunity to work on an innovative project for a leading conversational AI company in the MENA region. The goal was to enhance their fintech chatbot capabilities using state-of-the-art Large Language Models. This blog post details the process, challenges, and outcomes of this exciting endeavor.
The Challenge
The company aimed to improve the accuracy of their fintech chatbot in categorizing customer inquiries into relevant departments such as financing & leasing, bank cards, bank channels, and payment operations. My task was to explore and implement advanced language understanding capabilities using cutting-edge LLMs.
Data Preparation and Methodology
Working with a substantial dataset of around 100,000 Arabic customer inquiries, I extracted a representative sample of 1,000 conversations. This approach balanced the need for meaningful analysis with computational efficiency.
The data preparation process involved:
- Careful sampling to maintain dataset diversity
- Translating Arabic text to English using the GoogleTranslator api
- Post-translation processing, including manual review and privacy-preserving generalization
- Feature selection focusing on inquiry descriptions and main category labels
Sample of raw data before cleaning:
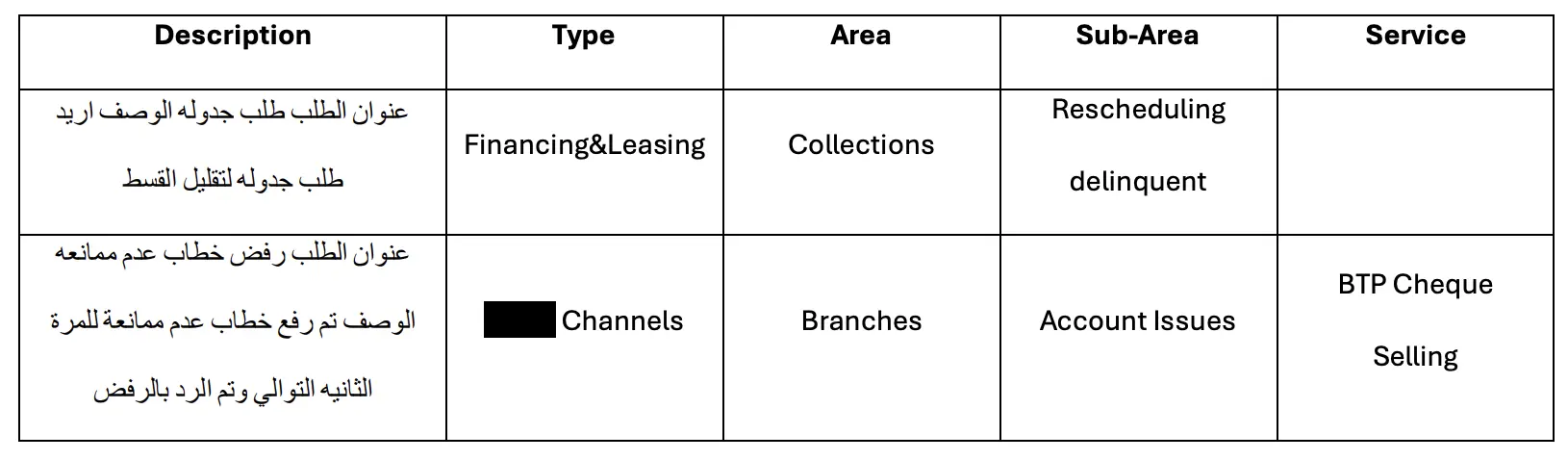 This image shows a snapshot of the original Arabic customer inquiries before processing.
This image shows a snapshot of the original Arabic customer inquiries before processing.
Sample of data after translation and post-processing:
 This image displays the same data after translation to English and anonymization.
This image displays the same data after translation to English and anonymization.
Models and Approaches
I evaluated several models and approaches:
- llama3-8b and llama3-70b:
- Zero-shot learning
- Few-shot learning
- Fine-tuning (for llama3-8b)
- Claude-3.5-sonnet:
- Zero-shot learning
- Few-shot learning
This comprehensive evaluation allowed me to compare the impact of model size, different learning paradigms, and model architectures on fintech inquiry classification.
Zero-Shot and Few-Shot Implementation
A key part of the work involved implementing zero-shot and few-shot learning approaches. Here’s an example of the functions developed:
def zero_shot_classification(description, types):
prompt = f"""Given the following text: "{description}"
Classify it into one of the following categories:
[Financing & Leasing, Payment Operations, Bank Channels, Bank Cards]
Output only the category name, nothing else."""
response = ollama.chat(model='llama3', messages=[{'role': 'user', 'content': prompt}])
return response['message']['content'].strip()
def create_few_shot_prompt(text, examples):
prompt = "Here are some examples of text and their categories:\n\n"
for category, category_examples in examples.items():
for example in category_examples:
prompt += f"Text: {example}\nCategory: {category}\n\n"
prompt += f"Now, classify the following text into one of the categories. Output only the category name, nothing else:\n\nText: {text}\nCategory:"
return prompt
These functions demonstrate the process of crafting effective prompts for LLMs, a crucial aspect of leveraging these powerful models for specific tasks.
Implementation
The project utilized a combination of local and cloud-based resources:
- Local: MacBook Pro with 36GB RAM for zero-shot and few-shot inferences
- Cloud: Google Colab with T4 GPU for fine-tuning
The software stack included Python, PyTorch, and Hugging Face Transformers. This setup allowed for efficient processing of both local tasks and more computationally intensive operations.
For fine-tuning, I employed QLoRa (Quantized Low-Rank Adaptation), an efficient technique allowing for fine-tuning of large models on consumer-grade hardware. This approach enabled the optimization of large language models within the constraints of available computational resources. The results of the QLoRa fine-tuning process over three epochs are shown below:
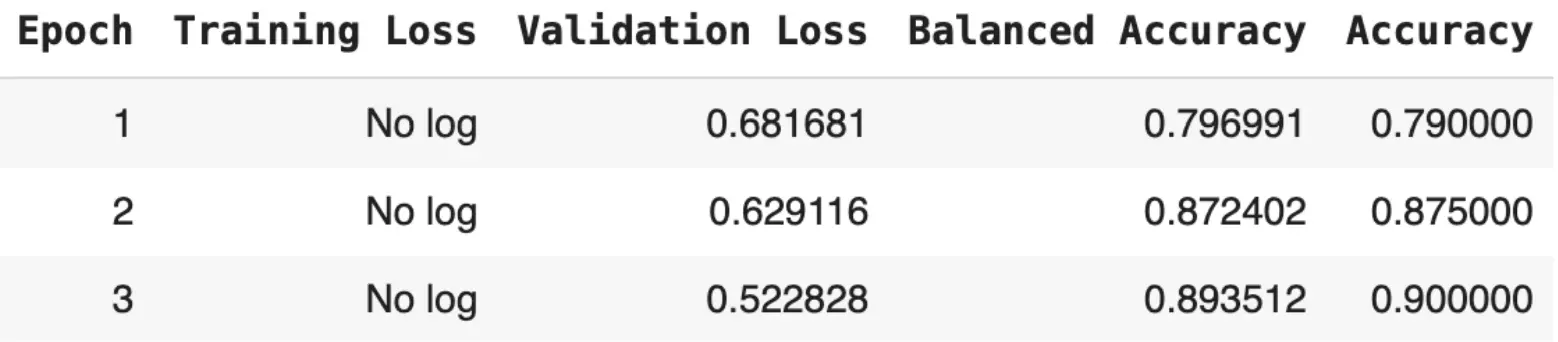 This table illustrates the improvement in model performance across epochs, showcasing decreasing validation loss and increasing accuracy as the model learns.
This table illustrates the improvement in model performance across epochs, showcasing decreasing validation loss and increasing accuracy as the model learns.
Results and Analysis
The evaluation yielded significant insights:
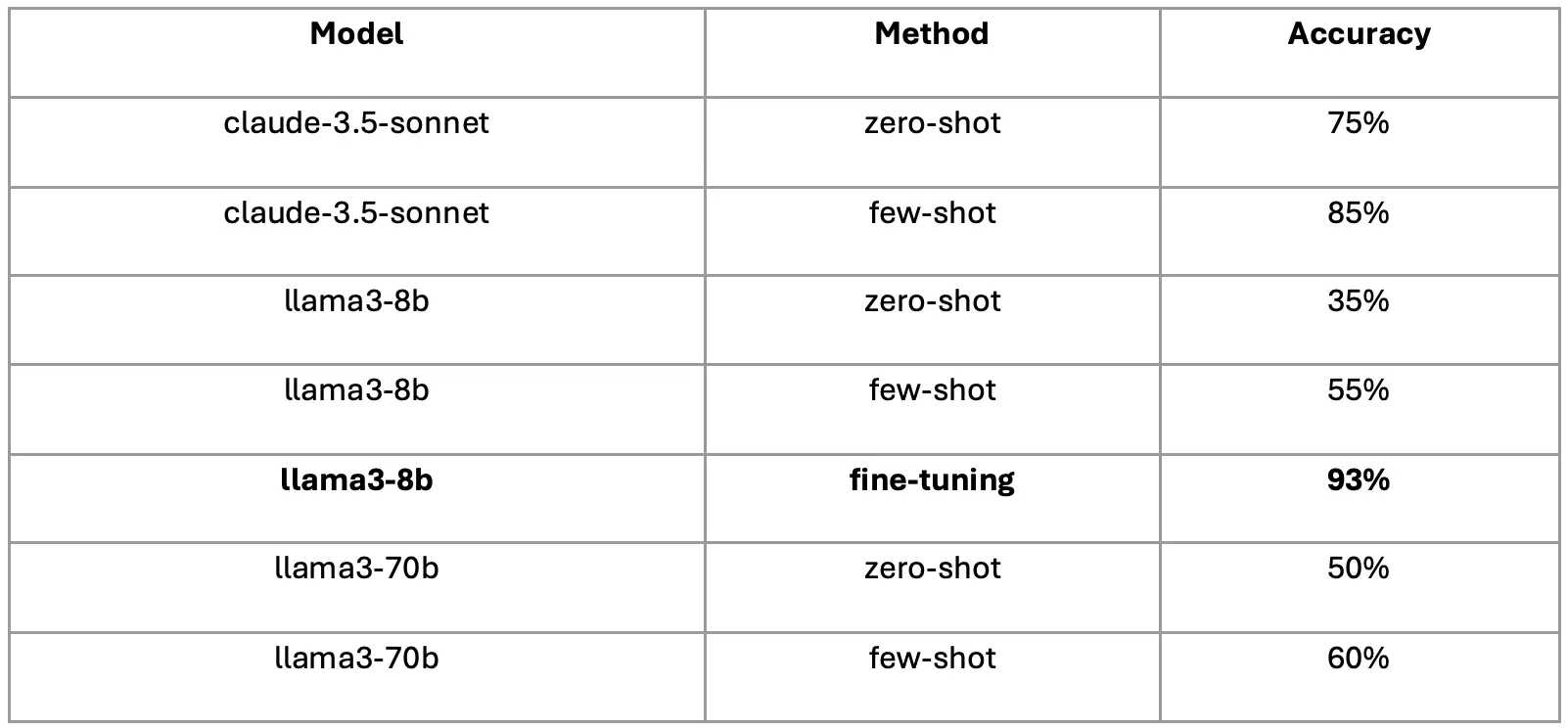
Key findings:
- Fine-tuned llama3-8b achieved an impressive 93% accuracy
- Few-shot learning consistently outperformed zero-shot across all models
- Claude-3.5-sonnet demonstrated superior zero-shot and few-shot capabilities
I also benchmarked the llama3-8b model on the standard Banking77 dataset for comparison:

Deep Dive into the Results
- The improvement from 55% (few-shot) to 93% (fine-tuned) accuracy for llama3-8b underscores the power of task-specific training.
- The consistent improvement from zero-shot to few-shot learning across all models (e.g., Claude-3.5-sonnet improving from 75% to 85%) demonstrates the value of providing minimal examples for model adaptation.
- The modest improvements of llama3-70b over llama3-8b (50% vs. 35% in zero-shot, 60% vs. 55% in few-shot) reveal the importance of considering the trade-offs between model size and performance gains.
- Claude-3.5-sonnet’s superior performance in zero-shot and few-shot tasks highlights the variability in model architectures and their suitability for different learning paradigms.
- The performance discrepancy between our custom dataset and Banking77 (82% few-shot accuracy) emphasizes the impact of dataset characteristics on model performance.
Implications for Fintech Chatbot Development
The project findings have several important implications:
- The superior performance of fine-tuned models suggests prioritizing task-specific training for production systems.
- The strong performance of few-shot learning, particularly with advanced models like Claude-3.5-sonnet, offers a viable strategy for quick prototyping and adaptation to new inquiry categories.
- The analysis of model size impact provides guidance on balancing performance gains with computational costs.
- The challenges posed by translation highlight the potential value of developing Arabic-language models for the MENA region, opening avenues for future research and development.
Conclusion
This project demonstrated the potential of LLMs in enhancing fintech chatbot classification. The fine-tuned llama3-8b model’s 93% accuracy underscores the value of task-specific training, while the strong few-shot capabilities of Claude-3.5-sonnet offer flexibility for rapid prototyping.
The work provides a roadmap for implementing more efficient, accurate, and adaptable chatbot classification systems in the dynamic landscape of financial technology. By balancing the power of fine-tuned models with the flexibility of few-shot learning, fintech companies can significantly enhance their customer service capabilities.
As the field of AI continues to evolve, the insights gained from this project contribute to the ongoing development of AI applications in specialized domains like fintech, particularly in multilingual and region-specific contexts.
Link to the full project on GitHub