
As an avid football fan and data enthusiast, I’ve always been fascinated by the intersection of sports and technology. This passion led me to create statsbrew, a web platform designed to provide real-time injury data and lineup predictions for Fantasy Premier League (FPL) managers. In this blog post, I’ll walk you through the development process, the technologies used, and the impact of this project.
The Concept
The idea behind statsbrew was to create a one-stop solution for FPL managers seeking up-to-date information on player injuries and the likelihood of players starting in upcoming matches. By combining web scraping, data processing, and AI-generated narratives, I aimed to provide valuable insights that could inform fantasy team decisions.
Key Features
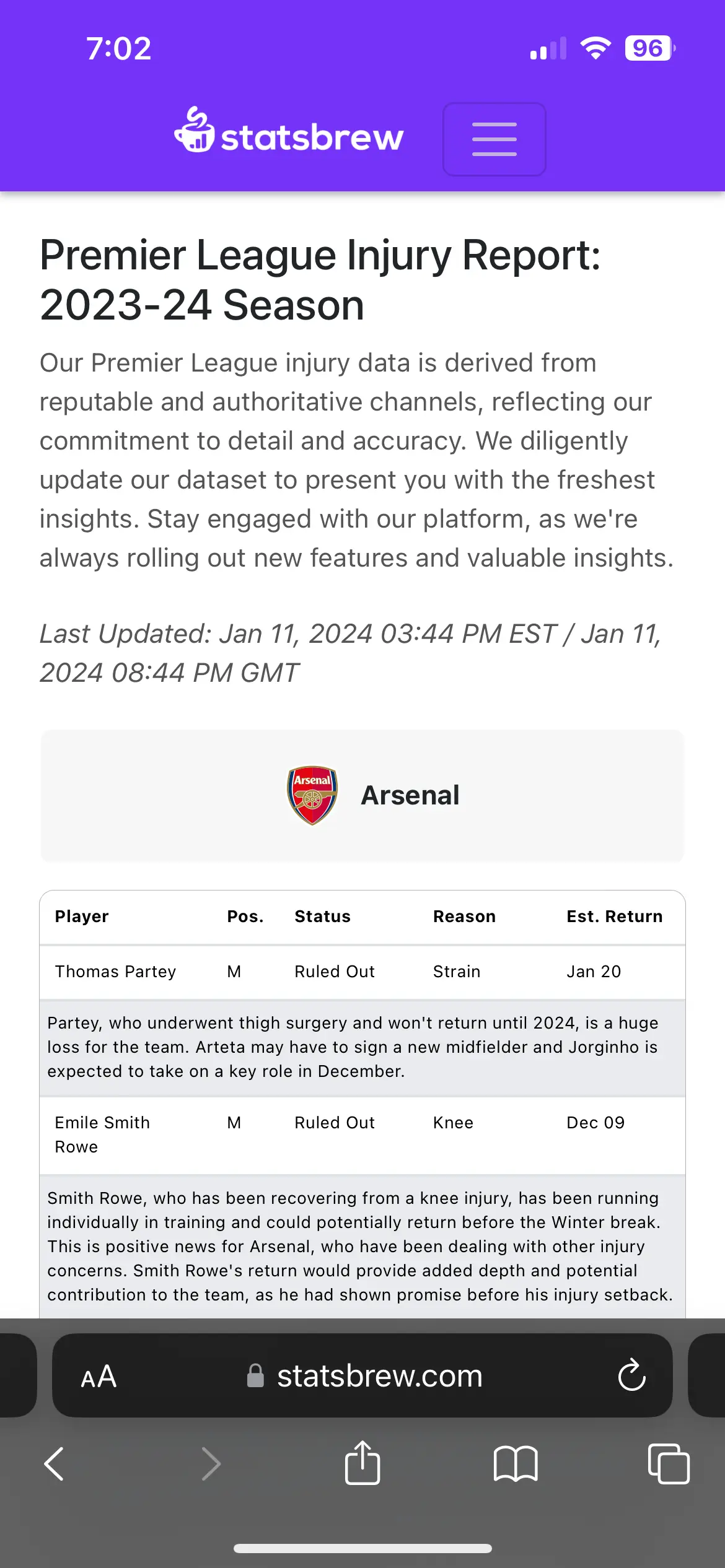
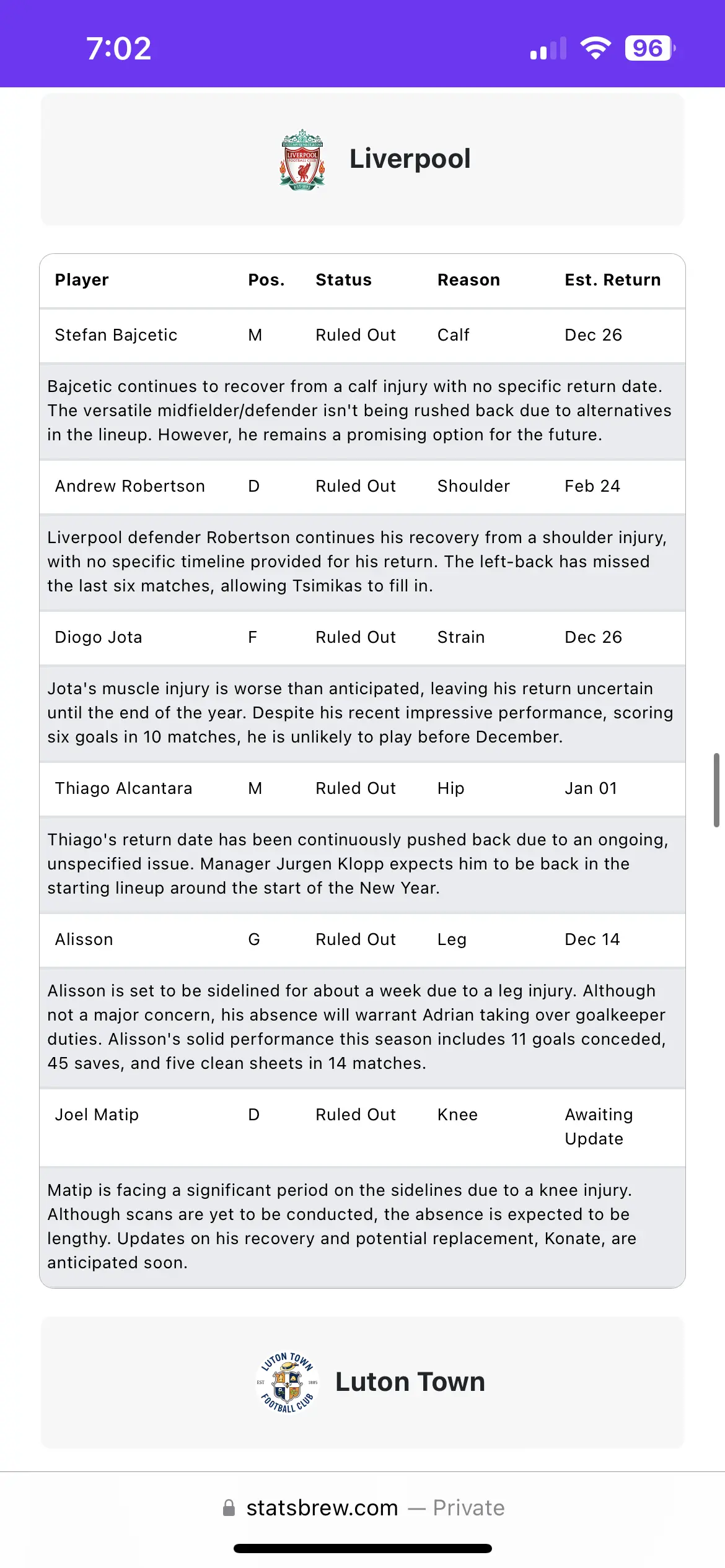
- Injury Data Tracking: Real-time updates on player injuries, including injury type, expected return dates, and AI-generated descriptions.
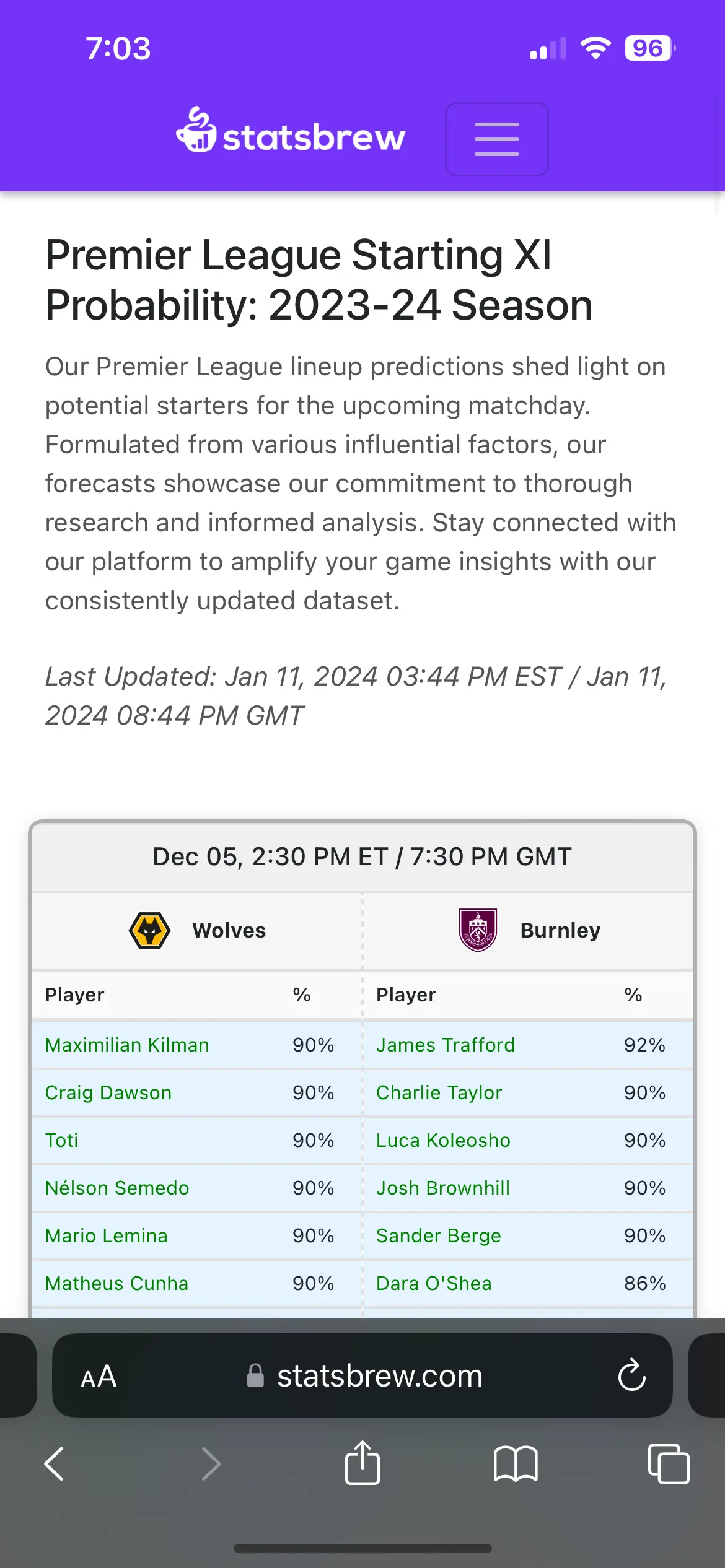
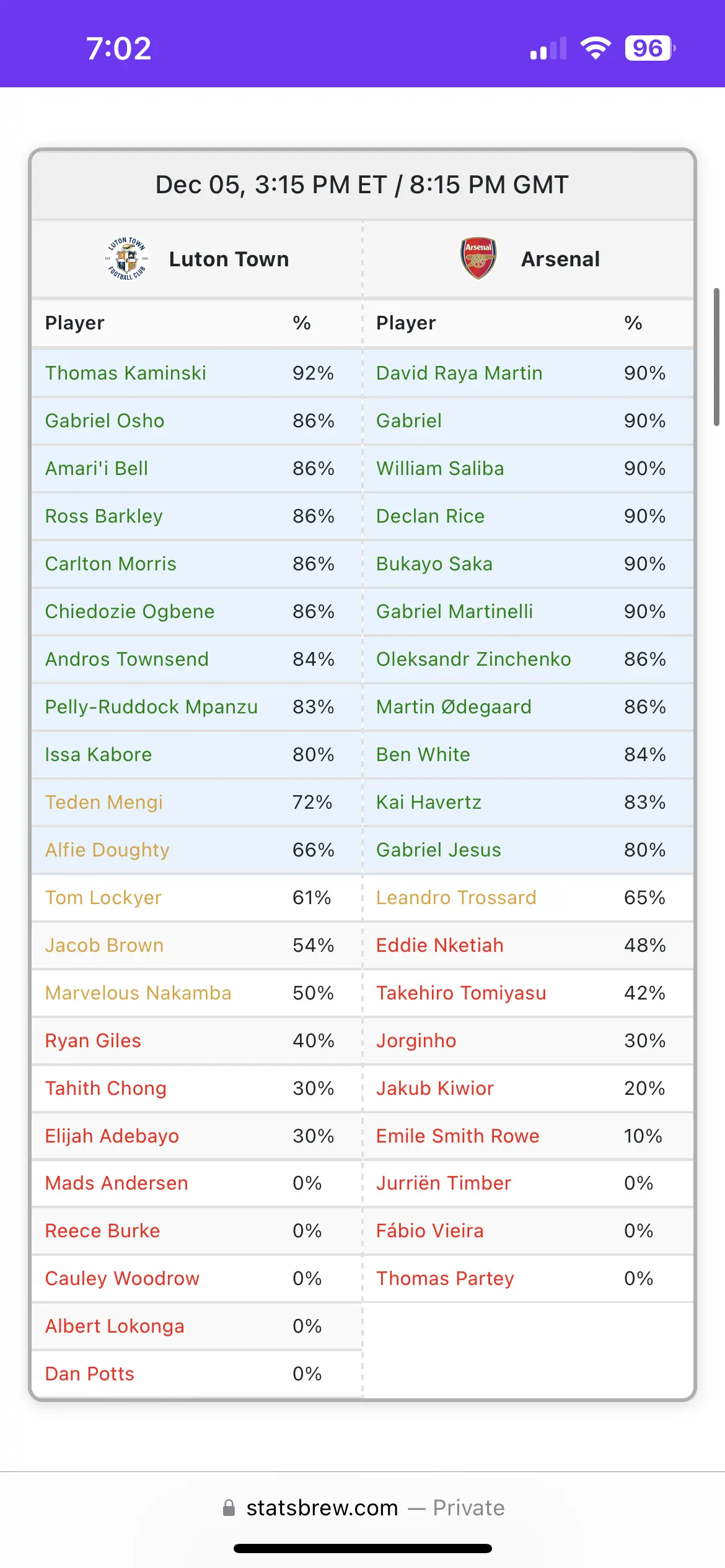
- Starting Probability Predictions: A custom algorithm to calculate the likelihood of a player starting in the next match.
- Mobile-Responsive Design: Ensuring a seamless experience across devices.
- Twitter Integration: Automated tweets for injury updates to reach a wider audience.
Technology Stack
- Backend: Python with Flask
- Frontend: HTML, CSS
- Database: SQLite
- AI Integration: LangChain and OpenAI API
- Data Scraping: BeautifulSoup, Selenium
- Deployment: Hosted on a cloud platform (Heroku)
Development Process
1. Data Collection
The first step was to gather data from various reliable sources. I used BeautifulSoup and Selenium to scrape injury information and player statistics from Premier League websites. Here’s a snippet of the scraping process:
from bs4 import BeautifulSoup
import requests
url = "data-scraped-site-example.com"
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36',
}
html_content = requests.get(url, headers=header).text
soup = BeautifulSoup(html_content, "lxml")
# Extracting injury data
player_rows = soup.findAll('tr', class_='player-row')
for player_row in player_rows:
name = re.findall('Player(.*)', player_row.find_all('td')[0].text)[0]
reason = re.findall('Reason(.*)', player_row.find_all('td')[1].text)[0]
#...
2. Data Processing
After collecting the raw data, I processed it to create meaningful insights. This involved cleaning the data, mapping team names, and calculating starting probabilities. The probability calculations were based on the accuracy of the sites I scraped data from, which themselves considered factors such as recent performances and whether a player started in the previous game. By combining and weighting data from multiple sources, I aimed to provide a more comprehensive and accurate prediction of starting probabilities.
3. AI-Generated Narratives
To provide more context to the injury data, I integrated OpenAI’s GPT model to generate concise reports for each player. This was done using the following process:
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI(openai_api_key="your-api-key")
for index, row in main_df.iterrows():
script = f'''
I possess a table featuring soccer player names, and
their injury or game status. My primary objective is to deliver concise player status reports...
Description 1 : {row['Description_site1']}
Description 2 : {row['Description_site2']}
Description 3 : {row['Description_site3']}
Analysis : {row['Analysis']}
'''
AI_outputs.append(chat_model.predict(script))
4. Web Application Development
I used Flask to create the backend of the web application, serving the processed data to the frontend. The frontend was built using HTML and CSS, with a focus on creating a responsive design that works well on both desktop and mobile devices.
Here’s a simplified version of the Flask route for the injury report page:
@app.route('/injury-report')
def injury_report_updated():
injuries_df = pd.read_csv('injuries_df.csv')
return render_template('injuries.html', injuries=injuries_df.to_dict('records'))
5. Twitter Integration
To expand the reach of statsbrew, I integrated Twitter API to automatically tweet about new injuries or significant updates. This was implemented using the tweepy library:
import tweepy
client = tweepy.Client(
consumer_key=CONSUMER_KEY,
consumer_secret=CONSUMER_SECRET,
access_token=ACCESS_TOKEN,
access_token_secret=ACCESS_TOKEN_SECRET
)
def generate_tweet(entry):
team = entry['Team']
player = entry['Player']
reason_description = reason_mapping[entry['Reason']]
status_phrase = status_map_phrases[entry['Status']]
status_emoji = status_emoji_map[entry['Status']]
projected_return = entry['Est. Return']
report = entry['Report']
team_short_name = hashtag_mapping[team]
tweet = (f"{status_emoji} #FPL Alert! 🚨\n"
f"{team} {status_phrase} {player} due to {reason_description}.\n"
f"📅 Estimated Return: {projected_return}\n"
f"For the extended report, check out: https://www.statsbrew.com/injury-report\n"
f"#PremierLeague {team_short_name}")
return tweet
for _, row in df_new.iterrows():
tweet_text = generate_tweet(row)
client.create_tweet(text=tweet_text)
Here’s a screenshot showing some example tweets automatically generated by statsbrew:
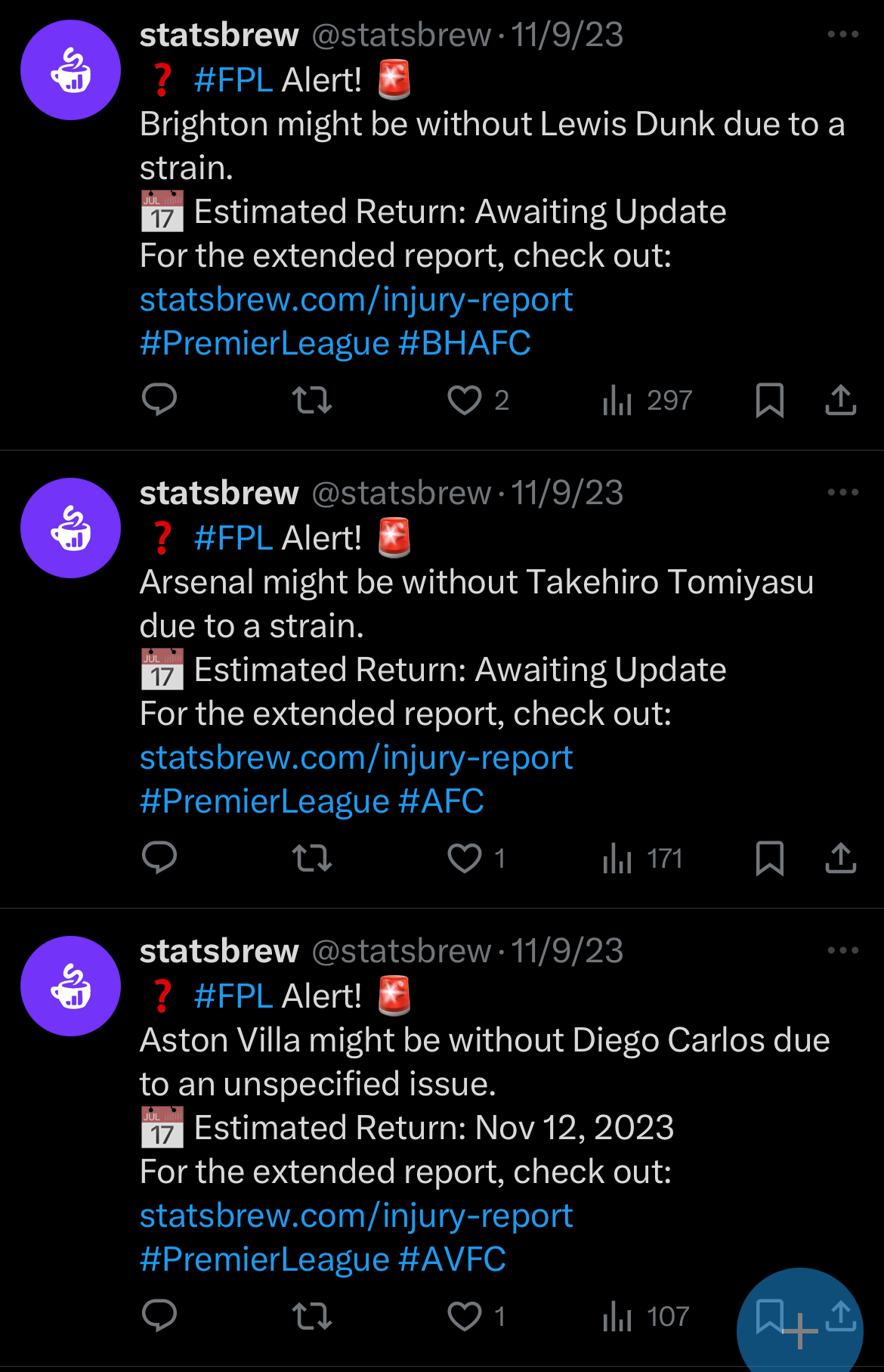
These automated tweets helped keep FPL managers informed about the latest player updates in real-time, further extending the utility of the statsbrew platform.
Results and Impact
Within two months of launching statsbrew, the platform attracted over 1,000 unique visitors. The site reported on more than 500 players, providing valuable insights to FPL managers around the world.
Desktop Views
Here are several views of statsbrew’s desktop interface:
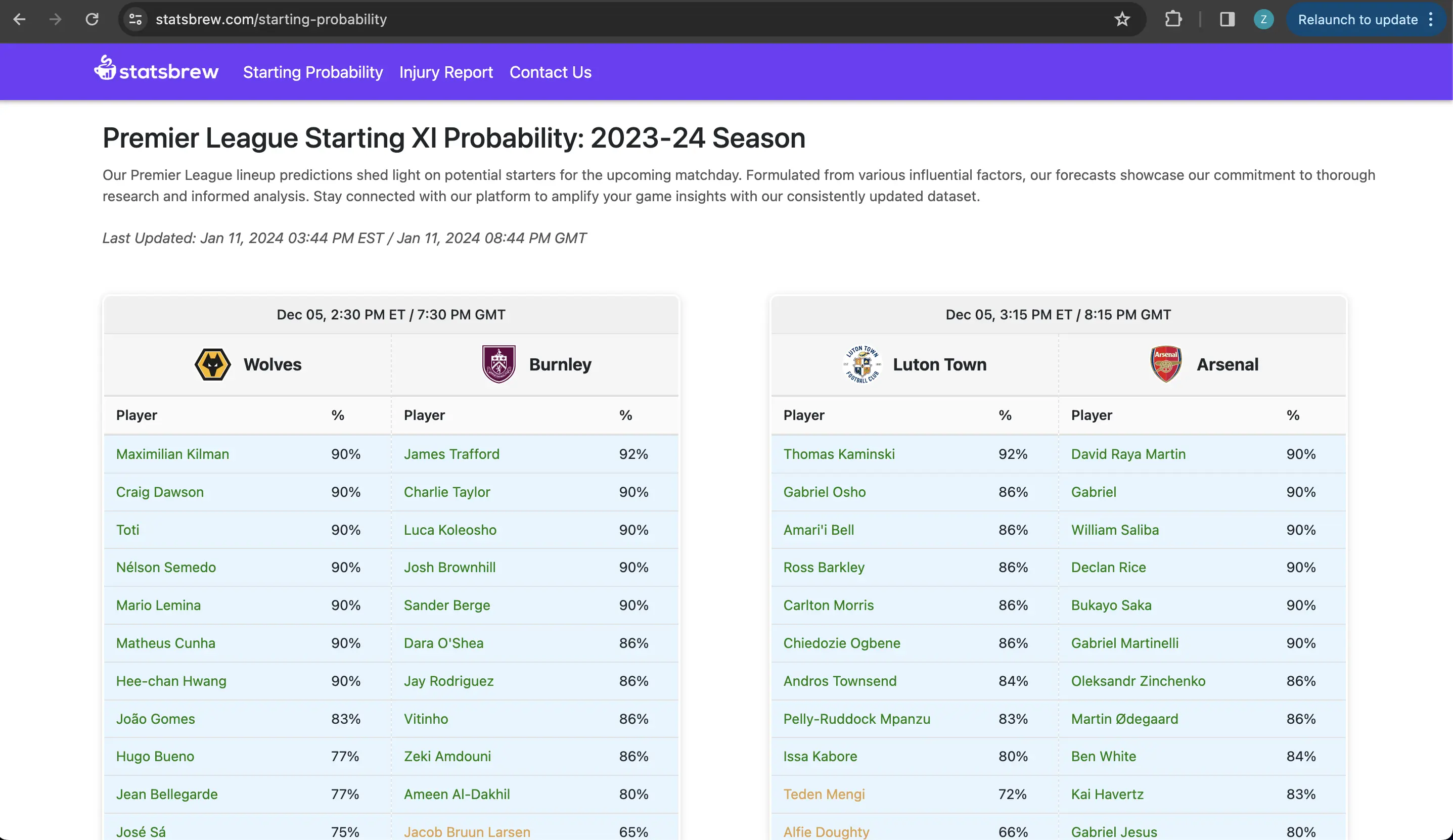
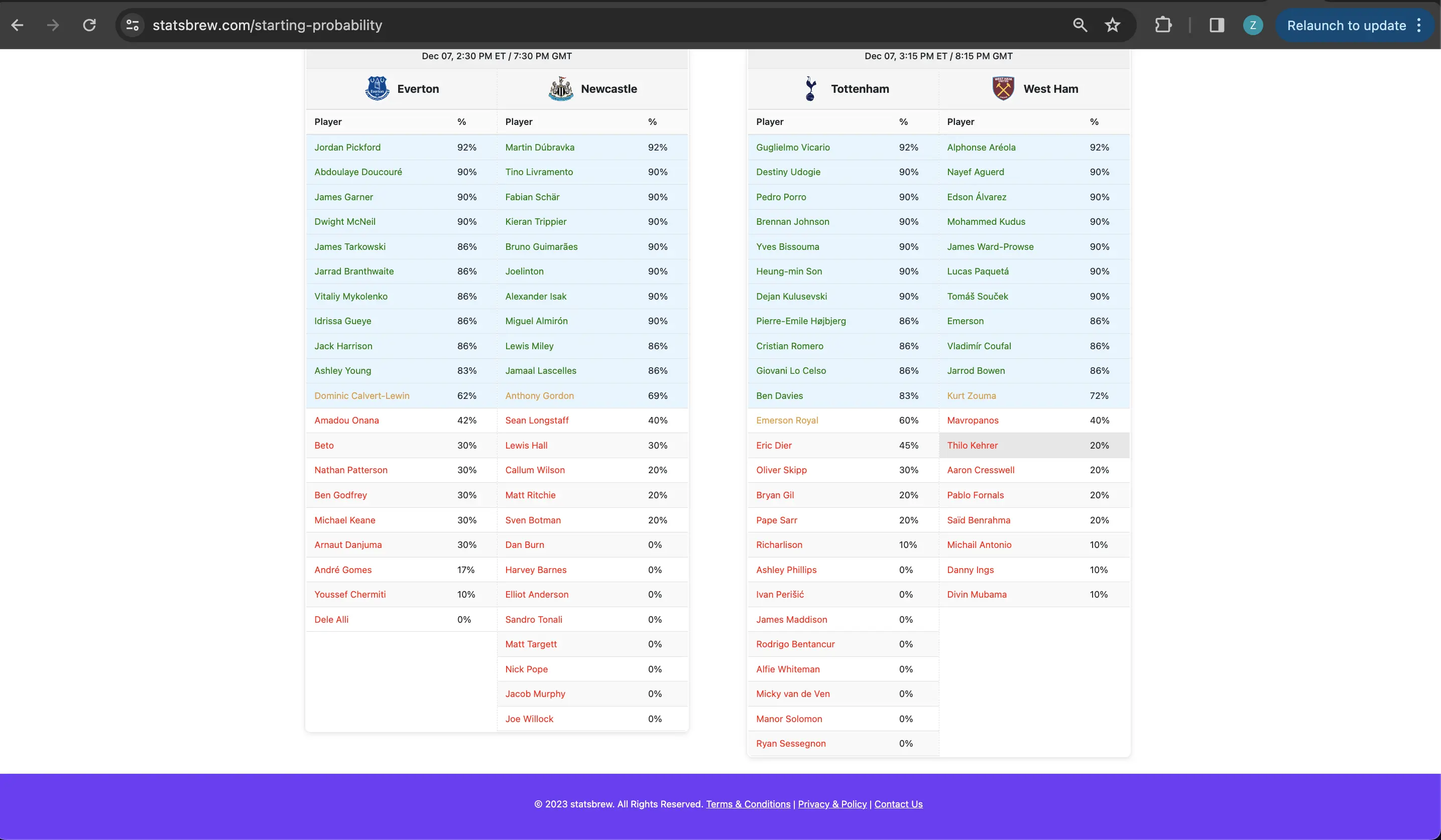
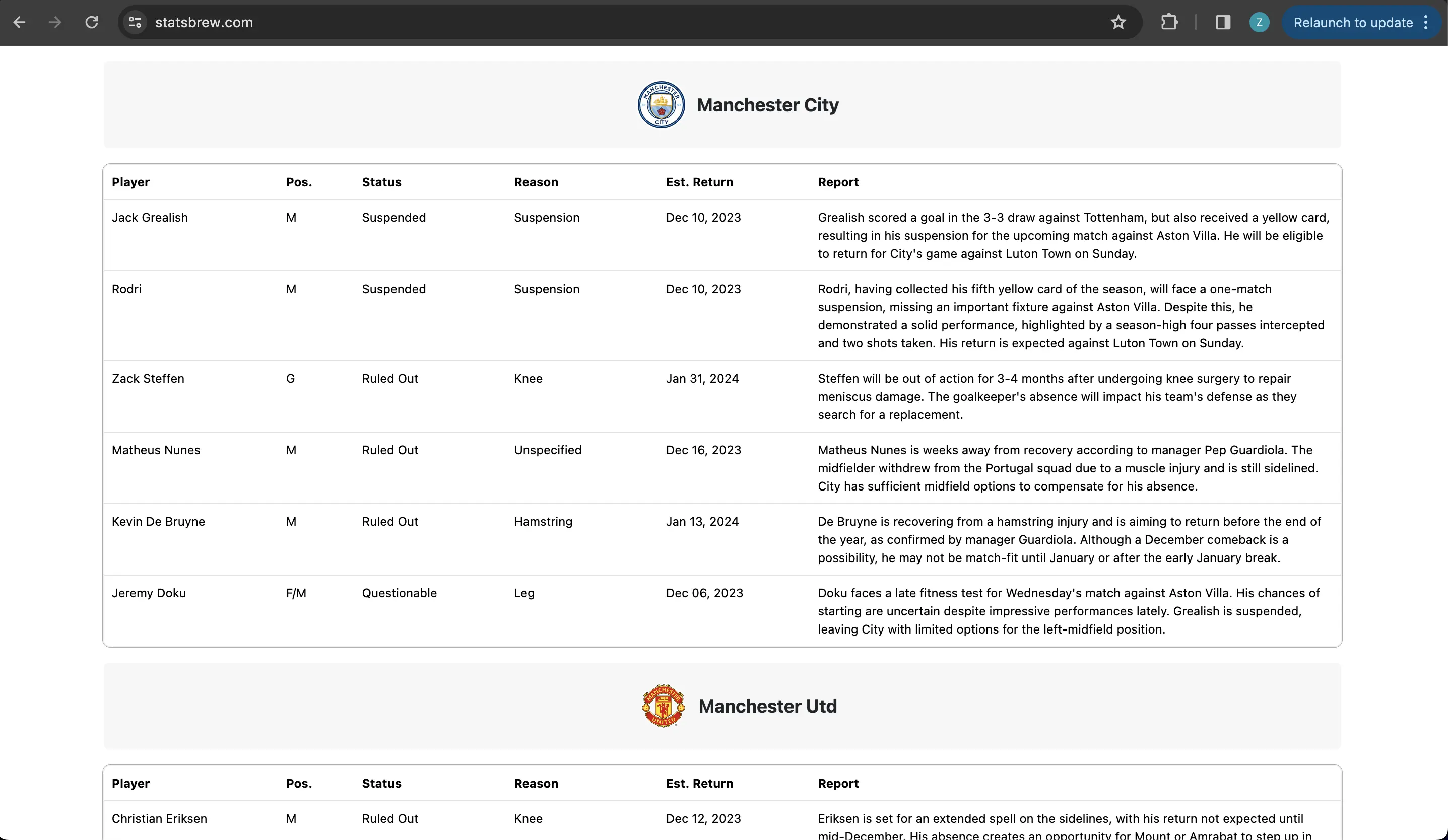
Mobile Views
statsbrew was designed with mobile users in mind. Here are some views of the mobile interface:
Challenges and Learnings
Developing statsbrew came with its share of challenges:
- Data Accuracy: Ensuring the scraped data was accurate and up-to-date required constant refinement of the scraping algorithms.
- Dynamic Player Database: Appending the database with new player names and data, especially when players transferred to Premier League clubs, posed a challenge. This required implementing systems to detect and integrate new player information seamlessly.
- AI Integration: Fine-tuning the AI-generated narratives to provide relevant and concise information took several iterations.
These challenges provided valuable learning experiences in web scraping, data processing, and integrating AI into web applications.
Current Status and Future Plans
While statsbrew has been well-received by its users, I’ve temporarily discontinued the service to focus on improvements and new features. Throughout its operation, I continuously refined the platform based on user feedback, ensuring it met the needs of FPL managers.
Future Plans:
- Implementing user accounts for personalized team tracking
- Adding more advanced statistical analysis and visualizations
- Expanding coverage to other football leagues
Conclusion
Building statsbrew has been an exhilarating journey that merged my passion for football with my software development expertise. This project has not only enhanced my technical skills in web development, data processing, and AI integration but also provided valuable insights into user needs and effective data presentation in the sports analytics domain.
The positive feedback and engagement from users have been a great source of motivation. As I work on improving and expanding statsbrew’s capabilities, I’m excited about the potential to continue making a meaningful impact in the FPL community.
The intersection of sports and technology offers endless possibilities, and projects like statsbrew are just the beginning. As we move forward, the fusion of real-time data, predictive analytics, and user-friendly interfaces will undoubtedly continue to transform how we engage with and enjoy sports.